Introduction
The web currently works in silos. Every platform operates as an autonomous system. So every organization, for example, Google, has its database of users and a unique identifier for every user. This identifier can be an email, a phone number, etc. If a user on Google wants to sign up on Facebook, they'll need to go through another signup process, as Facebook has no idea who the user is within Google's system. Solutions like social login have been helpful, but primarily, every platform requires a signup process. If Facebook wants to implement a feature to allow the user to fetch all their images on Google photos and post them on Facebook, Facebook and Google will have to communicate and this should happen via an API (Application Programmable Interface). This interface is necessary, primarily because the unique identifiers of the user on Facebook and Google databases will be different. Google will demand something that represents a unique identifier on their systems, maybe a Gmail address and Facebook will have to provide this to get meaningful results.

API Rules
So for Facebook to fetch a user's photos from Google, they'll need to access Google's APIs and adhere to certain rules.
- Facebook will need Access keys and secrets to obtain third-party access to Google's APIs. These access keys can be revoked by Google at any time.
- The requests will be rate-limited, as Google wouldn't want you overloading their infrastructure.
- Google will need to keep these photos available via the API else Facebook will lose access to this information.
With these few rules, there are already too many variables, and this isn't a robust solution if we want to achieve maximum interoperability. Also, if Facebook wanted to allow their users to reuse their Twitter bios on Facebook, that will require another third-party request to Twitter, and it is clear how this can quickly spiral into a web of third-party dependencies, albeit hanging on a very small thread.
Solution
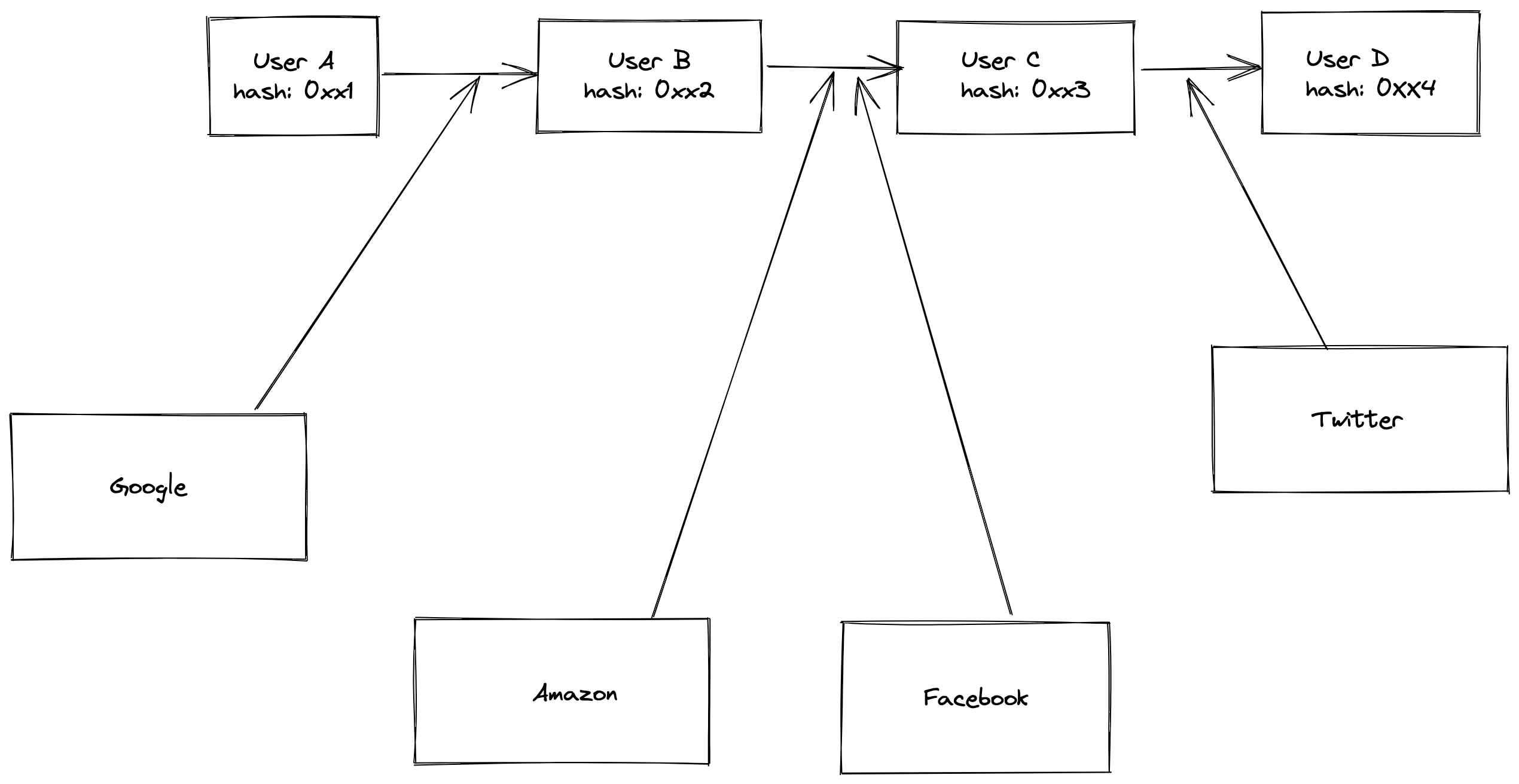
One solution can be making the database publicly accessible and verifiable. Unique identifiers are no longer localized and can be globally verifiable hashes that can be used across different autonomous systems. A globally verifiable unique ID can negate the need for multiple email addresses, phone numbers, etc. This database will be a Layer 1 infrastructure and different organizations can build up the stack. Much is still left to be desired, for one, there'll be a need for private databases, as not all information should be publicly accessible. This privacy is similar to what the Taproot upgrade on the Bitcoin network is trying to solve, but with a publicly accessible and verifiable database, intercommunication will become smoother.